
728x90
728x90
SMALL

💡 요약
- 데이터 기반 제품 개선이란?
- 데이터 과학자의 역할 · 스킬셋
- 모델 개발 과정
- 데이터 기반 제품 개선 케이스
- 머신러닝이란?
- 머신러닝 정의
- 머신러닝 모델이란?
- 머신러닝 종류
- 지도 기계 학습
- 비지도 기계 학습
- 강화 학습
- 머신러닝 모델 개발 시 고려할 점
- MLOps란?
- MLOps VS DevOps
- 머신러닝 사용 시 고려할 점
💭 느낀 점
어제는 데이터 기반 의사결정과 관련된 내용을 배웠다면, 오늘은 다음 단계인 머신러닝 모델에 관해 배웠다.
데이터 팀에서 데이터 분석가가 데이터를 분석해 의사결정에 도움을 주고 난 후에 벌어질 액션은 데이터 과학자가 그에 맞는 머신러닝 모델을 개발하여 서비스에 적용할 수 있도록 해주는 일이다. 머신러닝이라는 말은 워낙 많이 들어봤기 때문에 대략적으로 뭔지는 알았지만, 이렇게 원론적인 이야기를 들을 기회는 없었다. 역시나 수업 내용이 한 번에 이해될만큼 쉽지는 않았던 것 같다. 굉장히 깊은 머신러닝이라는 분야를 겉핥기로 한 번 쓱 훑은 느낌이랄까? 앞으로 이 부분은 공부할 양이 어마어마할 것 같다!
그래도 마지막에 Simple ML for Sheets를 활용한 간단한 실습은 머신러닝이 그렇게 어렵고 복잡한 것만은 아니라는 걸 느끼게 해주었다. 물론 실무에서는 복잡한 머신러닝이 기본이겠지만, 간단히 생각해보면 데이터 셋에서 비어있는 데이터를 다른 행을 기반으로 예측하는 것 자체도 머신러닝이라고 할 수 있는 것이다. 수업 내내 머신러닝이라는 게 어렵게 다가왔었는데, 마지막 실습을 하고 나니 내가 할 수 있는 수준으로 먼저 이해하고 그걸 점진적으로 발전시키는 것도 나쁘지 않겠다는 생각이 들었다🙂
🌳 데이터 기반 제품 개선이란?
데이터 기반 제품 개선이란?
- 머신러닝 기술을 활용해 제품/ 서비스의 기능을 개선하는 것
데이터 과학자의 역할
- Product Science
- Decision Science : 데이터 분석가의 역할
- 머신러닝 형태로 사용자들의 경험을 개선
- 문제에 맞춰 가설 수립 → 데이터 수집 → 예측 모델 빌딩 → 테스트
- Agile 방법으로 수행
- Waterfall 방법 : 시간도 오래 걸리고 실수하면 되돌리기 힘듦
- 훈련 데이터 중 일부를 테스트용으로 남겨두고 나머지로 모델 빌딩 → 남겨둔 테스트용 데이터로 테스트 진행
- A/B Test : 사용자들에게 직접 노출시켜서 확인하는 방법
데이터 과학자에게 필요한 스킬셋
- 머신러닝/인공지능에 대한 깊은 지식과 경험
- 코딩 능력 (Python, SQL)
- 통계 · 수학 지식
- 끈기, 열정
- 현실적인 접근 방법
- Agile 기반의 모델링
- 딥러닝이 모든 문제의 해답은 아님
- 과학적인 접근 방법
- 지표 기반 접근
- 모델링을 위한 데이터의 존재 여부
모델 개발 과정 (Life-Cycle)
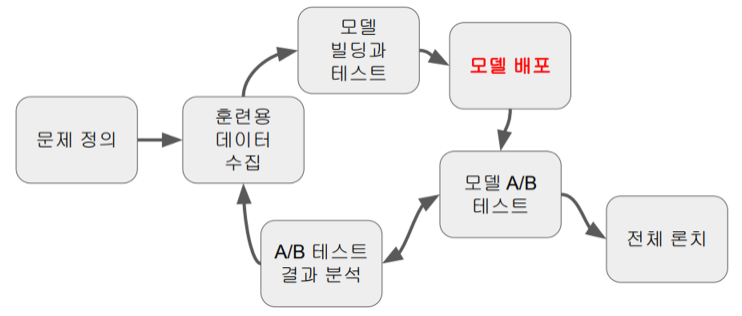
- 문제 정의 → 훈련용 데이터 수집 → 모델 빌딩 & 테스트 → 모델 배포 → A/B 테스트
→ 전체 런칭 OR A/B테스트 결과 분석 후 다시 사이클 시작
데이터 기반 제품 개선 케이스
- 개인화된 추천 엔진
- 규칙 기반 → 머신러닝 기반
- 사기 결제 감지
- 훈련 데이터 수집 : 실제 사례 수집(기업과 협업), 이상값 탐지 실행
- 과정에서 ‘머신러닝 편향성’ 또는 ‘머신러닝 윤리’의 중요성
ex) A 나라 남자가 범죄를 저지른 이력 → A 나라 모든 남자가 범죄자는 아님
- 환자 이상 징후 예측 (ex) 원격 환자 모니터링
- 농업용 자율 트랙터
- 의료 이미지(Medical Imaging) 분석
- 딥러닝 알고리즘이 MRI, X-ray 이미지 분석 (ex) VoxelMorph
- Caption Health : 초음파 사진 기반의 심장병 진단 기술 개발 → 인공지능 기반의 이미징 기술로 FDA 승인 받음
🌳 머신러닝이란?
머신러닝(Machine Learning) 정의
- ‘A field of study that gives computers the ability to learn without being explicitly programmed’ (Arthur Samuel)
- 프로그래밍 하지 않고 학습할 수 있는 능력을 컴퓨터에게 부여하는 학문 분야
- ‘배움이 가능한 기계의 개발’
- 데이터의 패턴을 보고 흉내내는 방식 (Imitation)
- 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
- 인공지능(AI) > 머신러닝(ML) > 딥러닝(DL)
머신러닝 모델이란?
- 머신러닝 모델 : 머신러닝을 통해 최종적으로 만드는 것
- 입력 데이터를 기반으로 특정 방식의 예측을 해주는 블랙박스 → 지도 기계 학습(Supervised ML)
- 데이터 과학자가 머신러닝 트레이닝/빌딩 → MLOps가 모델을 실제 서비스에 배포
🌳 머신러닝 종류 - 지도 기계 학습
지도 기계 학습(Supervised Machine Learning)
- 명시적 예제(트레이닝 셋)를 통해 학습 → 정답이 존재 (ex) 개냐 고양이냐!
- 트레이닝셋 : 훈련 데이터
- 레이블/타겟 필드 : 모델이 예측해야 하는 필드
- 문자열을 그대로 쓸 수 없음 → 어떤 형태건 숫자로 바꿔줘야 함 (ex) 남자면 1, 여자면 2
- Feature Engineering : 트레이닝셋으로부터 새로운 필드를 뽑아내는 것
- 주어진 훈련 데이터를 조금 더 사용하기 편한 형태로 변환하는 것
지도 기계 학습 종류
- 분류 지도 학습(Classification)
- 이진 분류(Binary)
- 다중 분류(Multi-class)
- 회귀 지도 학습(Regression)
- 예측 대상이 유한한 카테고리가 아니라 연속적인 숫자일 때 (ex) 주택가격 예측 등
지도 기계 학습 예시
- 타이타닉 승객 생존 여부 예측
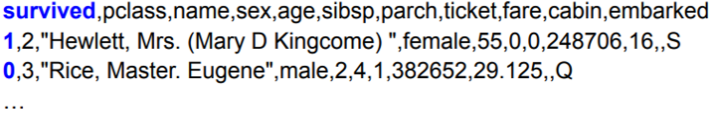
- 이진 분류 문제 (ex) 생존 여부 → 0 or 1
- ‘survived’ : 레이블/타겟 필드
(1이면 생존 / 0이면 사망)
- 스팸 웹 페이지 분류기

- A → 문자열을 숫자의 집합으로 만들어 줘야 함
지도 기계 학습 단계
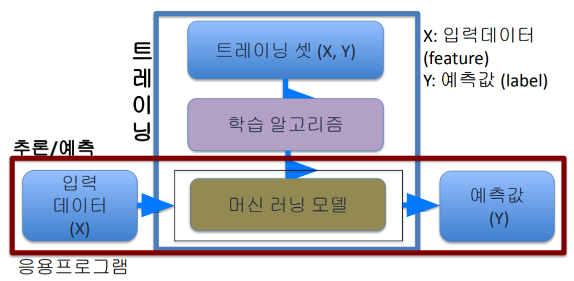
- 트레이닝 셋 (X, Y)
- Y : 예측 값(Lable) → 예측해야 하는 대상
- X : 입력 데이터(Feature) → 나머지 모든 필드
- 전처리를 통해 데이터를 수치화 및 삭제 → 수치 데이터들도 범위를 맞춰주는 표준화를 해야 함
- 추론/예측
- 모델 배포 → 머신러닝 모델에 예측 필요 → 입력데이터(X) API로 넣어줌 → 예측 값(Y) 리턴
- 머신러닝 모델 배포 및 서비스에서 추론/예측이 필요 → MLOps 직군이 생김
🌳 머신러닝 종류 - 비지도 기계 학습
비지도 기계 학습(Unsupervised Machine Learning)
- 데이터를 특정 기준에 따라 그룹화
비지도 기계 학습 예시
- Language Model : 문장의 일부를 보고 비어있는 단어를 확률적으로 예측
- 위키피디아에 있는 자연스러운 문장들을 대상으로 훈련
- GPT
- 지도/비지도학습 사이의 머신러닝
- 초거대 언어 모델 (LMM : Large Language Model)
🌳 머신러닝 종류 - 강화 학습
- 게임 같은 환경
- 알파고 : 규칙 아래에서 어떻게 하면 이기고 지는지 학습
- 자율주행
🌳 머신러닝 모델 개발 시 고려할 점
데이터 과학자 VS 엔지니어
- 모델 개발(데이터 과학자) → 모델 배포(엔지니어)
- 본인의 업무만 생각할 게 아니라 프로세스 전체를 생각해야 함
- 개발부터 배포까지 가능한 운영환경에서 작업해야 함
모델 개발 시 기억해야 할 점
- 모델 개발이 끝이 아니라 최종 런칭 및 운영까지 관여
- 피드백 루프 : 운영에서 생기는 데이터를 가지고 개선점 찾기
- 주기적으로 모델을 재빌딩 및 배포 → MLOps 직군 탄생
- 엔지니어와 모델 개발 초기부터 런칭까지의 과정을 구체화하고 소통
- 모델 개발시 모델을 어떻게 검증할 것인지?
- 모델을 어떤 형태로 엔지니어들에게 넘길 것인지? 피쳐 계산을 어떻게 하는지? 모델 자체는 어떤 포맷인지?
- 모델을 프로덕션에서 A/B 테스트할 것인지? 한다면 최종 성공판단 지표가 무엇인지?
- 개발된 모델이 바로 프로덕션에 런칭 가능한 프로세스/프레임워크 필요
- ex) 트위터 : 데이터 과학자들에게 특정 파이썬 라이브러리로 모델 개발 정책화
- 머신러닝 개발/배포 프레임워크 등장
- 머신러닝 모델 개발, 검증, 배포를 하나의 프레임워크에서 수행
- ex) AWS SageMaker가 대표적 → 검증된 모델을 버튼 클릭 하나로 API 형태로 런칭 가능
- ex) 우버 / 리프트 / 넷플릭스 등의 IT기업도 자체 머신러닝 개발/배포 프레임워크 개발
- ex) Google Cloud, Azure 등
🌳 MLOps란?
MLOps
- 모델 빌딩 → 배포 → 성능 모니터링
- 모델 빌딩 → 배포 자동화
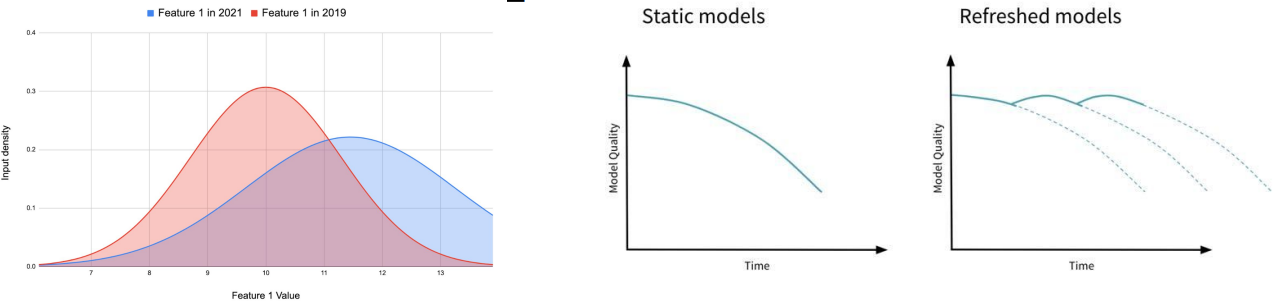
- Data Drift로 인한 모델 성능 저하 관리
- ML 모델에서 가장 중요한 것은 훈련 데이터
- 시간이 지나면서 훈련 데이터와 실제 환경의 데이터가 다르게 변화 → Data Drift
- 주기적으로 ML 모델 재빌딩 필요
- 모델 서빙 환경, 성능 저하 모니터링 → 필요 시 Escalation 프로세스 진행
- Latency : 실행시간
DevOps
- MLOps와 차이점
- MLOps : 데이터 과학자의 ML 모델이 대상
- DevOps : 개발자의 코드가 대상
- 개발자가 만든 코드를 시스템에 반영(CI / CD)
- CI : 개발자가 코드를 변경할 때마다 문제 여부 테스트
- CD : CI가 문제 없이 끝난 코드를 자동으로 프로덕션에 배포
ex) 구매 버튼을 빨간색으로 변경 : 테스트가 성공 → 코드가 자동으로 프로덕션에 들어가 구매 버튼이 빨간색으로 바뀜
- 시스템 모니터링
- 이슈 감지 시 Escalation 프로세스 진행 (공지)
- 문제가 해결될 때까지 트러블 슈팅 → 문제 해결되면 어떤 이유로 발생했는지 파악, 재발 방지
- On-call 프로세스
- 코드부터 서비스 운영까지 전체 프로세스를 관리
- 서비스 안정성 측면에서 굉장히 중요한 역할 → 경험이 많아야 함
MLOps 엔지니어가 알아야 하는 기술
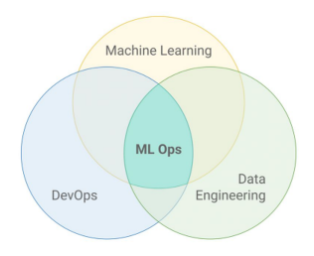
- 데이터 엔지니어가 알아야 하는 기술
- 파이썬 / 스칼라 / 자바
- 데이터 파이프라인 / 데이터 웨어하우스
- DevOps 엔지니어가 알아야 하는 기술
- CI / CD / 서비스 모니터링
- 컨테이너 기술 (K8S, 도커)
- 클라우드 (AWS, GCP, Azure)
- IaC(Infrastructure As Code) : 코드로 인프라 관리하기
- 머신러닝 관련 경험/지식
- 머신러닝 모델 빌딩, 배포
- 머신러닝 모델 빌딩 프레임워크 경험
🌳 머신러닝 사용 시 고려할 점
데이터 윤리
- 데이터 품질과 크기
- 데이터로 인한 왜곡(bias) 발생 가능
- ML Explainability : 내부 동작 설명 가능 여부(머신모델 모델이 왜 이렇게 예측했는지)
- 사용하는 훈련 데이터의 권리
데이터 기반 AI는 완벽한가?
- 트레이닝셋의 품질
- 미국 EMR/EHR(환자들의 의료 진료 기록)
- 법적인 소송 등의 용도로 쓰임 → 좋은 데이터인 것 같지만 그렇지 않음
- 그럴듯해 보이는 시스템에서 받은 데이터라고 해서 절대적으로 신뢰하면 안됨
- 미국 EMR/EHR(환자들의 의료 진료 기록)
- AI 도입시 가능한 문제들을 어떻게 해결할 것인가?
- 왜 어떤 결과가 나왔는지 설명이 가능한가?
- 알고리즘 자체에 특정 편향성이 있지는 않은가?
- 많은 시도와 실패 → 혁신을 만들어 낼 생태계와 법률이 필요
- 법률이 발전하는 기술을 따라가지 못 하고 있음
- EU의 AI 가이드라인 - Trustworthy AI
- 감독(human agency and oversight)
- 견고성과 안전성(robustness and safety)
- 개인 정보 보호 및 데이터 거버넌스(privacy and data governance)
- 투명성성(Transparency)
- 다양성과 비차별성과 공정성(Diversity, nondiscrimination and fairness)
- 사회/환경 친화적(Societal and environmental well-being)
- 문제 발생시 책임 소재(Accountability)
잘못된 개인정보 보존으로 인한 페널티
- HIPAA (Health Insurance Portability and Accountability Act)
- 미국의 개인 의료정보 보호법
- 개인을 식별할 수 있는 18개의 정보 보호
: 이름, 주소, 생년월일, 전화번호, 이메일 주소, 주민등록번호, 라이센스 번호, IP 주소, MRN( EMR/EHR에서 부여 받은 일련번호),
계좌 정보, 바이오메트릭(지문 등) 정보 등
- GDPR / CCPA
- EU / 미국의 개인정보 보호법
- 데이터 암호화 (ex) 데이터 저장 · 송수신 시 암호화 프로토콜 사용
🌳 [실습] 정의하고 차트 만들어보기
Simple ML for Sheets
- 구글 스프레드시트의 무료 확장판
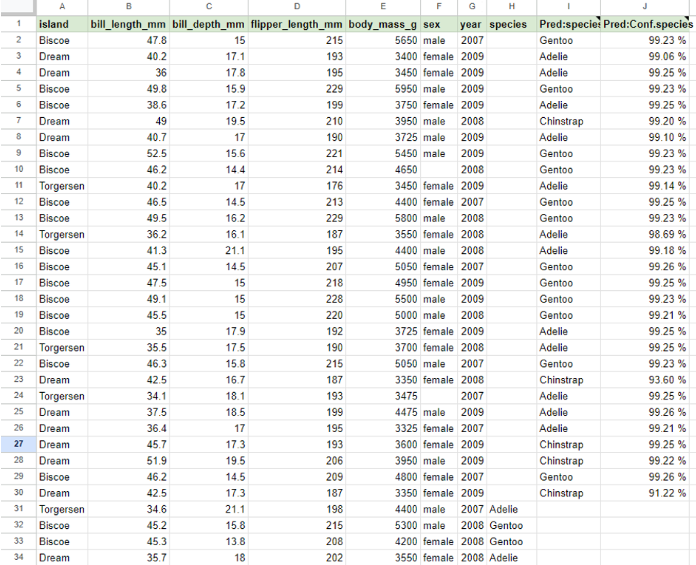
실습
- H열 : 타겟 필드
- 결과 : 예측값(I열), 확신도(J열)
- 보통 확신도가 50% 넘으면 선택함
본 내용은 프로그래머스 '데이터 분석 데브코스' 를 수강하며 작성한 내용입니다.
728x90
728x90
SMALL
'🐥 Education > 프로그래머스 데이터분석데브코스' 카테고리의 다른 글
| 프로그래머스 데이터 분석 데브코스|Week1|1주차 회고 (0) | 2023.11.24 |
|---|---|
| [TIL] 프로그래머스 데이터 분석 데브코스|Week1|데이터 활용 시 고려할 점 (0) | 2023.11.24 |
| [TIL] 프로그래머스 데이터 분석 데브코스|Week1|Gen AI를 이용한 생산성 증대 (1) | 2023.11.23 |
| [TIL] 프로그래머스 데이터 분석 데브코스|Week1|데이터 기반 의사결정 (1) | 2023.11.21 |
| [TIL] 프로그래머스 데이터 분석 데브코스|Week1|데이터 문해력이란? (0) | 2023.11.21 |