
728x90
728x90
SMALL

💡 요약
- Gen AI 란?
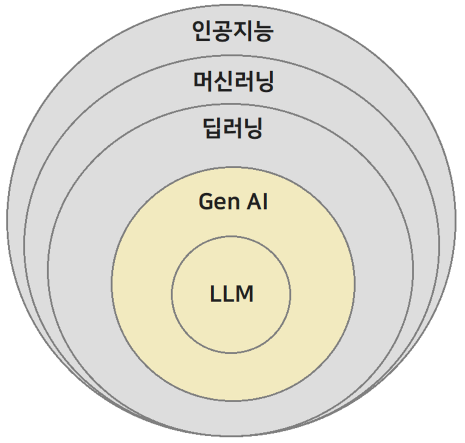
- 인공지능 > 머신러닝 > 딥러닝
- Gen AI > LLM
- 딥러닝의 모델 타입
- Gen AI 모델과 일반 ML 모델의 동작 방식
- Gen AI Foundation Model
- Gen AI Foundation Model 정의 · 종류
- Fine-Tuning
- Gen AI 모델
- Gen AI 모델 종류 · Hallucinations
- Gen AI 모델 종류 · Hallucinations
- 입력에 따른 Gen AI 모델
- Input이 Image인 경우
- Input이 Text인 경우
- Multi Modal Foundation Model
- Gen AI 사용 시 주의할 점
- MLOps VS DevOps
- MLOps VS DevOps
- GPT의 발전
- ChatGPT의 발전
- GPTs
- Gen AI 적용 케이스
💭 느낀 점
Gen AI를 주제로 ChatGPT까지 배워보는 시간이었다! Gen AI라는 기술, 그리고 그 안에 속한 LLM 기술이 현재 굉장한 영향력을 행사하고 있고 앞으로도 무한한 발전 가능성이 있겠다는 생각이 들었다. 특히나 Foundation Model을 Fine-Tuning 하여 다양한 모델을 만들어낼 수 있다는 부분이 굉장히 흥미로웠다. 앞으로 기업에서 이 부분이 얼마나 많이, 얼마나 다양하게 적용이 될지 궁금하기도 하고 현재 시점에서 이미 기업들에선 이 기술을 어떻게 사용하고 있는지 실무에서 직접 보고 싶었다.
오늘은 한기용 강사님의 특강도 진행이 되었다. 비전공자에 직무 전환을 하려고 하는 입장에서 IT직군 채용공고를 볼 때, 2~3년부터 많게는 5년 이상의 경력자를 찾는 회사를 많이 봤었다. 그 때마다 내가 설 자리는 없는 건가😢 불안하기도 했었는데, 강사님께서 2년까지는 신입을 뽑는다고 생각하고 일단 지원해보라고 하셨다. 그 말이 괜스레 힘이 되었다,,🤍 이력서에 다룰 수 있는 스킬을 그득그득 넣을 수 있는 그 날까지 화이팅💪
🌳 Gen AI 란?
인공지능 > 머신러닝 > 딥러닝
- 인공지능 : 인간이 하는 일을 대신 해주는 시스템을 만드는 컴퓨터 과학
- 머신러닝 : 인공지능의 일부
- 데이터에서 패턴을 찾아주는 블랙박스 형태
- 딥러닝 : 머신러닝의 일부
- 인공신경망을 사용해서 기존 머신러닝 알고리즘이 처리하지 못하는 복잡한 패턴을 처리
- 이미지/비디오/오디오 등의 복잡한 데이터 처리에 강점
Gen AI(Generative AI, 생성형 AI) > LLM(Large Language Model)
- 학습된 컨텐츠를 바탕으로 새로운 컨텐츠를 만드는 딥러닝 기술
- GPT : 입력 컨텐츠의 내용을 학습한 LLM
- LLM(Large Language Model)은 Gen AI의 일부
- 프롬프트를 바탕으로 대답을 예측하거나 새로운 컨텐츠를 생성
딥러닝의 모델 타입
- Discriminative
- Gen AI가 나오기 전의 모델 타입
- 분류/예측을 하는 것 → 레이블이 존재하는 데이터에 적용
- 지도 학습에 해당
- 피처(Input)들과 레이블(Output)들 간의 관계 학습
- (ex) 개 or 고양이 분류
- Generative
- 주어진 데이터의 패턴을 학습
- 훈련된 데이터의 통계적 특성을 이해 → 새로운 데이터 생성
- 비지도 학습에 해당
- (ex) 새로운 개 이미지 생성
Gen AI 모델과 일반 ML 모델의 동작 방식
- Gen AI는 ML 모델의 일부이기 때문에 동작 방식은 기본적으로 같음
- Input이 있을 때 예상되는 Output을 출력하는 형태로 함수(모델)을 학습하는 것
- y = f(x) → 달라지는 것은 출력값
- y : 출력 / f : 모델 / x : 입력
- 일반 ML 모델 → y는 보통 숫자, 카테고리, 확률 등
- Gen AI → y는 보통 자연어 문장, 이미지, 오디오 등
🌳 Gen AI Foundation Model
Gen AI Foundation Model 이란?
- 광범위한 데이터셋에 대해 학습된 대규모 머신 러닝 모델
- Pre-trained : 이미 일반적인 지식이 학습되어 있음
- 특별한 학습 없이 다양한 토픽에 적용 가능
- 정답이 있는 게 아니고 데이터셋 특성 학습이 목적 (Unsupervised Learning / Self Supervised Learning)
- 대용량 데이터로 학습 → 엄청난 시간, 돈, 인력 필요
- 트랜스포머 모델 아키텍처 사용 (Google ‘Attention is All You Need’ 논문에서 제안)
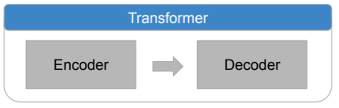
- 하나의 트랜스포머 안에는 Encoder, Decoder 존재
- 트랜스포머의 수가 늘어날수록
모델의 Power 확장 ↔ 학습 시간, 비용 증가
Gen AI Foundation Model 종류
- GPT-3, GPT-4 (Open AI) : 언어 모델
- BERT (Google) : 언어 모델
- T5
- DALL-E (Open AI) : 이미지 모델
Fine-Tuning
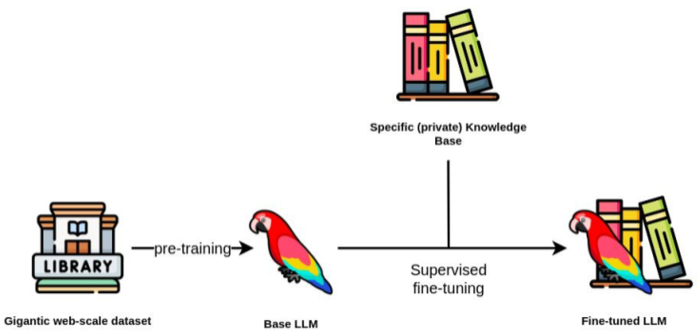
- 딥러닝에 일반적으로 존재하는 용어
- 파운데이션 모델을 변형하여 특정 지식을 재학습
- (ex) GPT → ChatGPT
- GPT : 문장을 주면 다음에 나오는 단어를 예측해주는 Base LLM
- ChatGPT : GPT에 대화하는 예제를 준 Fine-tuned LLM
🌳 Gen AI 모델
Gen AI 모델 종류
- Generative Language Models
- 훈련 데이터로 제공된 문장들로부터 언어 패턴을 학습
- 문장의 일부를 입력 받으면 다음 단어를 예측
- Generative Image Models
- Diffusion과 같은 기술을 사용해서 새로운 이미지를 만드는 모델
- 프롬프트를 입력으로 받아 이미지 생성
- 이미지를 입력으로 받아 특정 노이즈를 추가하여 이미지 변환
Gen AI 모델의 Hallucinations
- 모델이 부정확하거나, 무의미하거나, 완전히 조작된 정보를 생성하는 경우
- 사실 확인(Fact-Checking)이 항상 필요
- 발생 이유
- 훈련 데이터의 불충분
- 훈련 데이터의 최신성 부족
- 훈련 데이터의 품질 이슈
- 모델에게 충분한 요구사항이 주어지지 않음 → 프롬프트 디자인이 중요해짐
🌳 입력에 따른 Gen AI 모델
Input이 Image인 경우
- Output이 Image인 경우
- Super Resolution : 해상도가 낮은 이미지 → 해상도가 높은 이미지로 보정
- Image Completion : 배경 지우기, 공간에 가구 이미지 넣기 등
- Output이 Text인 경우
- Image Captioning : 이미지 설명
- Visual QA : 이미지에 대한 질의응답
- Image Search : 비슷한 다른 이미지 찾기
- Output이 Video인 경우
- Animation : 이미지를 비디오 형식으로 만들기
Input이 Text인 경우
- Output이 Image인 경우
- Image Generation : 이미지 생성
- Video Generation : 비디오 생성
- Output이 Text인 경우
- 입 · 출력이 Text → 가장 흔한 경우
- Translation : 번역
- Summarization : 요약
- Question Answering : 질의응답
- Grammer Correction : 문법 검사
- Output이 Audio인 경우
- Text to Speech : 문장 읽어주기
- Music Generation : 음악 생성
- Ouput이 텍스트, 미디어를 넘어서서 구체적인 Task를 하는 경우가 많아짐
- Coding Assistant : 코드 생성
- Virtual Assistant : 비서 역할
- Automation : 자동화
Multi Modal Foundation Model
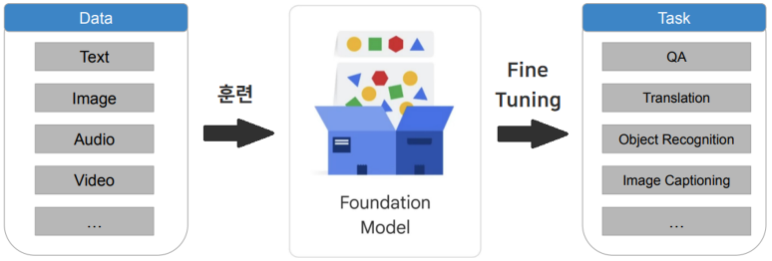
- Multi Modal : 하나의 모델이 여러 형태의 미디어를 서포트 하는 것
- 다양한 Data로 Foundation Model 생성 → 다양한 Task 가능
- ChatGPT 3, ChatGPT 3.5 → 하나
ChatGPT 4 → Multi Modal
🌳 Gen AI 사용 시 주의할 점
잘 사용하는 방법
- 블로그 또는 웹사이트를 위한 독창적인 콘텐츠 생성
- 예술 작품을 위한 영감 창출
- 빠른 프로토타입 및 목업 만들기
- 파일 변환 및 이미지 업스케일링과 같은 단순 작업 수행
- 업무 어시스턴트로 사용(코딩, 마케팅 등)
잘못 사용하는 방법
- 시험, 숙제 부정행위
- AI가 말하는 모든 것을 그대로 받아들이기 → 항상 사실을 확인해야 함
- AI를 사용하여 다른 아티스트의 작품 표절 → 저작권 침해 문제
Gen AI 문제점
- Microsoft, GitHub, OpenAI
- 코드 생성 AI인 Copilot → 라이선스 코드 무단 재사용 혐의로 집단 소송
- 너무 빠른 변화로 법제가 따라가지 못하고 있음
- AI 아트 툴 소송
- Midjourney : 웹 스크랩한 이미지로 모델 학습 → 아티스트의 권리 침해 혐의
- Getty Image VS Stability AI
- Stability AI가 Getty Image 자사 이미지를 무단 사용해 모델 훈련했다며 소송
- 나라에 따라 다른 입장
- 영국은 미국보다 텍스트 및 데이터 마이닝을 위한 콘텐츠 사용 허용에 비교적 적극적
- 사칭을 통한 사기, 가짜 뉴스 생성
- 노동 시장에 주는 잠재적인 악영향
- 많은 수의 스타트업들이 도산
- Stackoverflow : 트래픽 감소로 28% 인력 해고 (’23년 10월)
🌳 GPT의 발전
GPT (Generative Pre-trained Transformer)
- OpenAI에서 만든 초거대 언어 모델
- 훈련, 예측에 전용 하드웨어 사용
- LLM : Large Language Model
- 처음에는 두 가지 모델 제공
- Word Completion : 자연어에 적용한 모델 → 한국어 포함 다양한 언어 지원
- Code Completion : 코드에 적용한 모델 (ex) GitHub의 Copilot
- 네이버의 초거대 언어 모델 → Word Completion만 지원
GPT-3 vs GPT-4
- GPT-3
- 175조 개의 파라미터 = 800GB → 훈련 비용 $4.6M
- Context Window의 크기 : 2,048+1
- 2,048개의 단어가 입력되면 1개의 단어 예측
- 12,288개의 워드벡터 사용 (단어를 N차원의 공간에 맵핑)
- GPT-4
- 2023.3월에 공개
- 1,000조 개의 파라미터
- Context Window의 크기 : 8,192+1
- 32,768개의 워드벡터 사용
- Multi-modal (이미지 인식)
- GPT-4 Turbo
- OpenAI Dev Day에서 발표
- Context Window의 크기 : 128,000로 확장 → 모델의 정확도 개선
- API 기능 개선 : JSON 모드, 시드 제어, 다수 함수 동시 호출
- RAG 기능 제공 : 외부 문서, 데이터베이스 가져올 수 있음
- 정보 업데이트 : 2021년 9월 컷오프에서 2023년 4월로 갱신
경량 언어 모델들
- 초거대 언어 모델에 비해 학습, 추론이 훨씬 쉬움
- 메타의 llama
- 스탠포드의 Alpaca
- llama의 파인튜닝 버전
- 데이터브릭스의 Dolly
- ChatGPT 같은 대화 모델
🌳 ChatGPT의 발전
ChatGPT 소개
- 2022년 11월 30일 발표
- GPT를 챗봇의 형태로 Fine-Tuning
- RLHF : Reinforcement Learning from Human Feedback
- 사람 피드백 기반으로 대화하는 인공지능 모델 학습
- 강화학습 기법 활용하여 학습
- GPT의 지식을 챗봇 형태로 활용 가능
- Prompts 엔지니어링 탄생
- RLHF : Reinforcement Learning from Human Feedback
ChatGPT 용도
- 질문 답변
- 정보 추출
- 번역
- 대화 생성
- 글쓰기 지원
- 코드 생성 및 리뷰
- ···
ChatGPT 4.0
- 2023년 3월 발표
- 4.0부터는 월 $20
- 새로운 AI 모델 사용
- 8배 더 큰 Context Window 지원
- 최신 정보를 얻기 위한 인터넷 서핑 지원
- 플러그인 지원
- ex) 여행 리서치에 끝나는 것이 아니라 예약까지 연결
- 언어지원 개선 → 답변 개선
- 코딩과 관계된 기능 개선
- Code Interpreter 지원 → 데이터 분석 가능
- 코드 작성하고 Jupyter Notebook에서 실행 가능
- 샘플 데이터를 업로드해서 다양한 질문 가능
- 멀티모달 지원 : (이미지, 텍스트)
🌳 GPTs
GPTs
- 에이전트 기능 구현 (커스텀 챗봇)
- 특정 목적에 맞는 ChatGPT의 맞춤형 버전
- GPT Builder 기능 제공 → No Code 솔루션 (채팅으로 빌딩)
- Instructions, Expanded Knowledge, Actions로 구성
GPTs Store
- 내가 만든 GPT를 외부로 공유하거나 개인용으로 사용
- Revenue Sharing 제공 → GPTs를 잘 만들면 돈을 벌 수 있음
- API로도 제공
🌳 Gen AI 적용 케이스
- Quizlet
- OpenAI의 ChatGPT를 가지고 Find-tuning 한 Q-Chat이라는 AI 개인 튜터(챗봇)
- 다양한 토픽에 대해 일대일 채팅을 통한 학습 가능
- Duolingo
- 언어 학습 앱
- GPT-4로 두 가지 새 기능 구현
- Roleplay : AI 대화 파트너
- Explain my Answer : 실수할 때 문법 규칙을 세분화하여 설명
- Morgan Stanley
- 자산 관리와 관련된 방대한 내부 데이터 검색용 챗봇 개발을 위해 GPT-4 도입
- 내부 직원용 챗봇
- PDF 등 다양한 포맷으로 구성된 데이터 검색 수행
- Viable
- GPT-4를 사용하여 CS 티켓과 같은 자연언어 데이터 분석 수행
- OpenAI의 LLM을 Find-tuning 하여 비정형 데이터 분석용 모델 생성
- GPT-4를 사용하여 CS 티켓과 같은 자연언어 데이터 분석 수행
- Buzzfeed
- ChatGPT 초기 적용 사례
- 즉석 퀴즈 생성, 레시피 추천 챗봇 개발
🌳 [실습] Gen AI를 활용한 업무 자동화
Code Interpreter를 사용한 데이터 분석 (ChatGPT-4)
- 데이터 업로드 후 분석 요청
- 대화를 통해 계속적인 분석 요건을 구체화
- (ex) 평균 수명에 영향을 주는 가장 큰 변수가 무엇인지 상관관계 분석을 해주고 그래프도 그려줘
- (ex) 각 대륙별로 인구, 평균 수명, GDP 등의 지표가 어떻게 다른지 비교 분석해줘
실습
🔗 https://chat.openai.com/share/0086ec0e-a80c-45d9-98d7-e29767ccad07
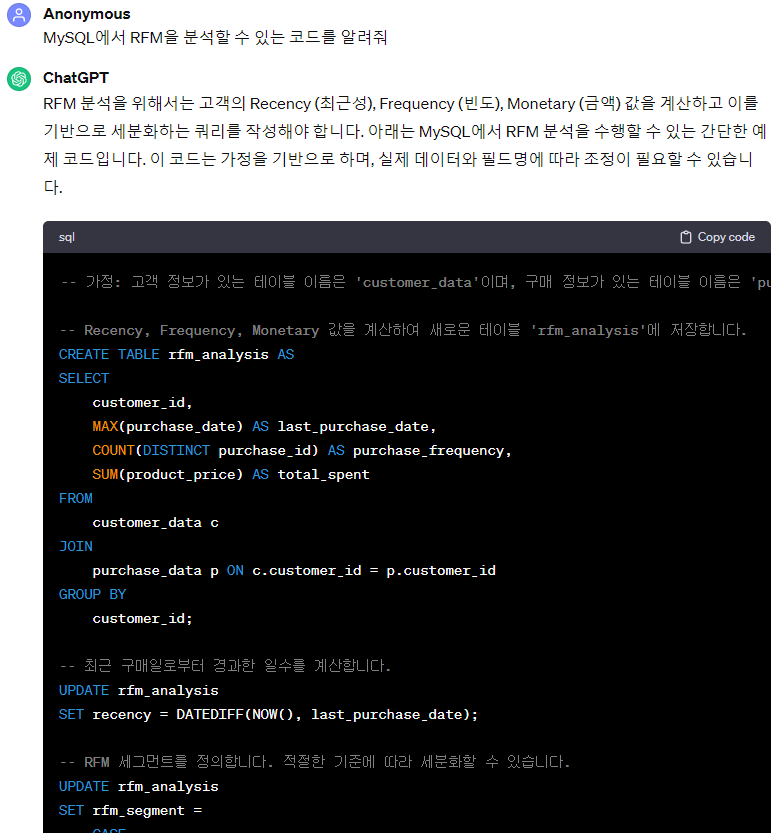
본 내용은 프로그래머스 '데이터 분석 데브코스' 를 수강하며 작성한 내용입니다.
728x90
728x90
SMALL
'🐥 Education > 프로그래머스 데이터분석데브코스' 카테고리의 다른 글
| 프로그래머스 데이터 분석 데브코스|Week1|1주차 회고 (0) | 2023.11.24 |
|---|---|
| [TIL] 프로그래머스 데이터 분석 데브코스|Week1|데이터 활용 시 고려할 점 (0) | 2023.11.24 |
| [TIL] 프로그래머스 데이터 분석 데브코스|Week1|데이터 기반 제품 개선 (1) | 2023.11.23 |
| [TIL] 프로그래머스 데이터 분석 데브코스|Week1|데이터 기반 의사결정 (1) | 2023.11.21 |
| [TIL] 프로그래머스 데이터 분석 데브코스|Week1|데이터 문해력이란? (0) | 2023.11.21 |